Scrum, la journée type d’un Product Owner
Scrum, la journée type d’un Product Owner
Infographie de la vidéo:
Traduction de la vidéo
- par Cédric Chevalérias -
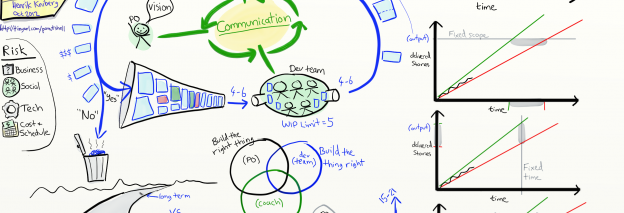
Parlons de développement logiciel Agile du point de vue du Product Owner (PO).
Voici Pat.
Elle est Product Owner.
Elle est vraiment passionnée par la vision qu’elle a du produit.
Elle ne connait pas le détail de ce que son produit va faire, mais elle sait pourquoi on fait ce produit, quels problèmes il va résoudre et pour qui.
Elle en parle tout le temps.
Voici les autres Parties Prenantes (PP).
Ceux qui vont utiliser, maintenir, ou être de près ou de loin concernés par le produit en cours de développement.
D’après la vision de Pat, tous ces gens vont adorer notre système, l’utiliser et en parler tout le temps.
Les besoins et les idées des PP sont exprimés comme des « histoires utilisateur » (US).
Par exemple, pour un système de réservation de vol, les gens doivent pouvoir chercher un vol.
Ça serait une des US.
Pat et les PP ont plein d’idées, Pat les aide donc à les convertir en US concrètes.
Maintenant, quelqu’un doit FABRIQUER le système.
Les voila : petite, co-localisée, multi-compétente, auto-organisée : l’équipe de développement.
Vu que c’est une équipe agile, ils ne gardent pas une grosse livraison complète pour la fin, mais ils livrent tôt et souvent.
Dans notre cas, ils livrent habituellement 4-6 US par semaine, c’est donc leur capacité.
La capacité est facile à mesurer : compter le nombre d’US livrées par semaine.
Certaines US sont grosses, elles comptent pour 2, d’autres sont petites, elles comptent pour la moitié.
Mais au final c’est environ 4-6 US par semaine.
Certains parlent de « story points », mais je dirai simplement des « User Stories », par semaine.
Pour maintenir ce rythme, et ne pas être embêté par des tests de régression manuels, l’Equipe a fortement investi dans des outils de tests automatiques et d’intégration continue (CI).
Donc chaque US a au moins un test d’acceptation automatique au niveau fonctionnel, et la majorité du code a des tests unitaires automatiques.
Le problème, c’est qu’il y a un paquet de PP qui demande plein de choses, et ils ne vont surement pas se limiter à 4-6 idées par semaine.
Ils ont PLEIN d’idées et PLEIN de souhaits.
Et chaque fois qu’on leur livre quelque chose, ça leur donne encore plus d’idées et ils demandent encore plus de trucs !
Que se passe-t-il si on essaie de leur faire plaisir, de faire tout ce qu’ils demandent ?
On est submergé.
Supposons que l’Equipe commence à travailler sur 10 nouvelles US par semaine.
Si on a 10 en entrée et 4-6 en sortie, l’Equipe sera surchargée.
Cela entrainera multitâches, démotivation et finalement une sortie plus faible et de mauvaise qualité.
C’est une proposition perdant-perdant.
C’est comme essayer de fourrer plus de papier dans une imprimante pour qu’elle imprime plus vite, ou ajouter encore des voitures sur une autoroute déjà saturée.
Ça ne marche pas : ça fait qu’empirer les choses.
Alors, on fait quoi ?
Le moyen d’éviter ce problème en Scrum et XP est appelé « la météo d’hier ».
L’Equipe dit : « ces dernières semaines, on a terminé 4-6 fonctionnalités par semaine. Donc quelles 4-6 fonctionnalités devrions-nous faire cette semaine ? ».
Le boulot du PO est de trouver, parmi toutes les US de l’univers, les 4-6 prochaines US à livrer.
L’approche Kanban consiste à limiter le TAF (Travail A Faire) ou WIP (Work In Progress).
Si l’Equipe décide que le nombre optimal de US à traiter simultanément est 5, ils ont appris que c’est juste assez pour occuper -sans surcharger- tout le monde, Ils ont donc décidé que leur limite de WIP est 5.
Dès qu’une US est terminée, une nouvelle sera acceptée, s’assurant ainsi que la limite de 5 US en cours ne sera jamais dépassée.
Ces deux approches fonctionnent bien ; comme l’équipe aura juste assez de travail pour travailler rapidement et efficacement; Avec un effet de bord cependant : il va se former une file d’attente en amont de l’Equipe, c’est ce qui, en Scrum, est appelé le Backlog Produit (PBL).
Cette file d’attente doit être gérée.
Si les PP persistent à demander 10 nouvelles US par semaine et que l’Equipe en réalise 4-6 par semaine, ça veut dire que la file grandira indéfiniment.
Avant d’avoir eu le temps de vous en rendre compte, vous aurez une liste de 6 mois dans le PBL.
Ce qui veut dire qu’en moyenne, chaque US réalisée répondra à un besoin exprimé 6 mois avant.
C’est agile ça ?
Il n’y a vraiment qu’une seule façon de ne pas perdre le contrôle de la file d’attente.
C’est le mot NON.
C’est le mot le plus important pour un PO, et Pat s’entraine tous les jours devant son miroir.
Dire OUI à une nouvelle demande est facile.
Surtout si ça veut simplement dire l’ajouter à un backlog qui ne fait que grossir.
Le travail le plus important pour un PO est de décider ce qu’il NE faut PAS construire, et penser aux conséquences de cette décision.
Et c’est pour ça que c’est difficile, bien sûr !
Le PO décide ce qui est embarqué et ce qui ne l’est pas.
Le PO décide aussi de l’ordre : ce qu’on fait maintenant, ce qu’on fait plus tard, et de la longueur que cette liste doit avoir.
C’est un travail difficile donc Pat ne le fait pas toute seule, elle le fait en collaboration avec les PP et l’Equipe.
Pour pouvoir prioriser, le PO doit avoir une idée de la valeur (métier) des US ainsi que de leur taille.
Certaines sont critiques, indispensables, alors que d’autres, des fonctionnalités bonus.
Certaines prennent quelques heures à faire, d’autres des mois.
Maintenant, devinez le rapport entre la valeur d’une US et sa taille ?
Et oui : aucun !
Plus gros ne signifie pas mieux.
Pensez à n’importe quel système que vous avez utilisé.
Je parie que vous pouvez penser à au moins une fonctionnalité vraiment simple, mais très importante, que vous utilisez tous les jours.
Je parie que vous pouvez penser à au moins une énorme fonctionnalité bien compliquée et qui n’a aucune importance.
La valeur et la taille, c’est ce qui aide Pat à prioriser intelligemment.
Comme ici : ces deux US ont à peu près la même taille, mais ont une valeur différente.
Donc faire celle-ci en premier.
Et là, ces deux US ont presque la même valeur, mais pas la même taille.
Donc faire celle-là en premier, etc.
OK, ça a l’air assez facile…
Mais, une seconde…
Comment connait-elle la valeur d’une US ?
Comment connait-elle sa taille ?
Et bien voici la mauvaise nouvelle : elle ne les connait pas.
C’est un jeu de devinettes.
Et c’est un jeu qui implique tout le monde !
Pat parle en permanence avec les PP pour voir ce qui a de la valeur pour eux.
Et elle parle en permanence avec l’Equipe pour voir ce qui est petit ou gros pour eux en termes d’effort d’implémentation.
Ce sont des estimations relatives, pas des nombres absolus.
Je ne sais pas combien pèse cette pomme ou cette fraise, mais je sais que la pomme est 5 fois plus lourde, et que la fraise a meilleur goût, du moins pour moi.
C’est tout ce que Pat doit savoir pour prioriser le PBL !
C’est plutôt cool comme ça.
Au début d’un nouveau projet, nos estimations sont forcément mauvaises.
Mais c’est OK, la plus grande valeur est en fait dans les conversations plutôt que dans les chiffres.
Et chaque fois que l’Equipe livre quelque chose aux vrais utilisateurs, on apprend quelque chose, et on devient meilleur pour estimer la valeur et la taille.
C’est pourquoi on estime et priorise en permanence.
Essayer de tomber juste dès le début est assez bête : c’est là qu’on en connait le moins.
La boucle de feedback est notre amie !
Cependant la priorisation n’est pas suffisante.
Pour livrer tôt et souvent, on doit décomposer les US en bouchées comestibles, de préférence juste quelques jours de travail par US.
On veut cette forme d’entonnoir sympa, avec des petites US bien claires à l’avant et des US plus vagues à l’arrière.
En faisant cette décomposition des US « juste à temps », on peut profiter des dernières connaissances sur le produit et les besoins utilisateur.
Tout ce dont on vient de parler – estimer la valeur et la taille des US, prioriser, décomposer – s’appelle habituellement l’« affinage » [ou l'entretien] du Backlog.
Pat mène un atelier d’affinage tous les mercredis de 11h à 12h.
Une heure par semaine.
Généralement, toute l’Equipe est présente, et parfois quelques autres PP.
Le programme peut varier un peu : on se focalise parfois sur les estimations, parfois sur la décomposition d’US, sur l’écriture de critères d’acceptation pour une US, etc.
J’espère que vous remarquez la thématique ici : la communication !
Le rôle de PO c’est avant tout de la communication.
Quand je demande à des PO expérimentés ce qu’il faut pour réussir, ils mettent généralement en avant la passion et la communication.
Ce n’est donc pas une coïncidence que le premier principe du manifeste agile soit « Individus et interactions avant processus et outils ».
Le rôle du PO n’est donc pas de nourrir l’Equipe à la petite cuiller avec des US.
C’est ennuyeux et inefficace.
Pat s’assure plutôt que tout le monde comprend la vision, que l’Equipe a un bon contact avec les autres participants, que les livraisons sont fréquentes et permettent un feedback rapide des vrais utilisateurs.
Ainsi l’Equipe apprend et peut prendre elle-même quotidiennement des décisions, permettant à Pat de se focaliser sur la vue d’ensemble.
Regardons quelques-uns des compromis qui doivent être trouvés par Pat et l’Equipe.
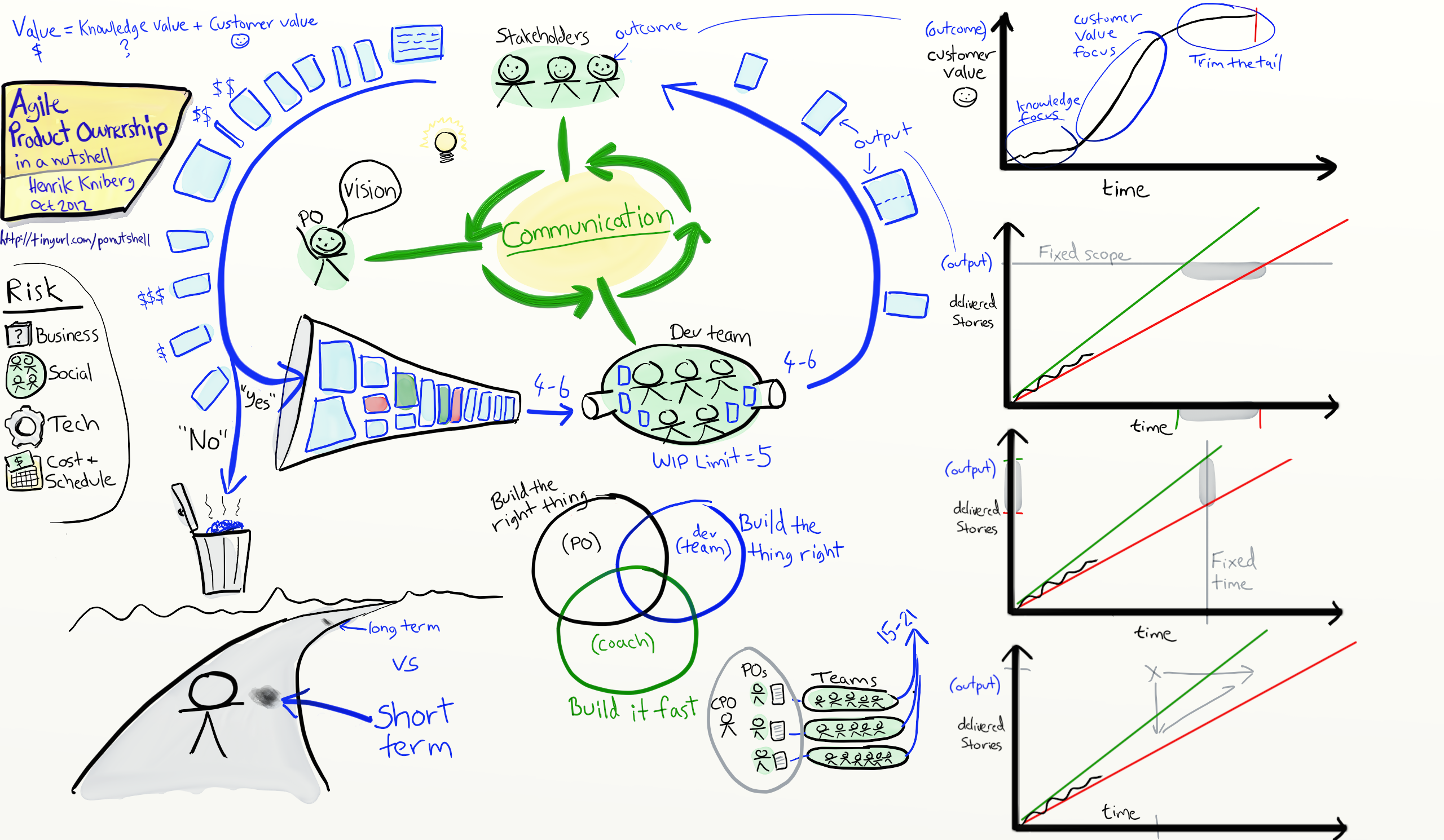
Il y a avant tout les compromis entre les différents types de valeur.
En début de projet, l’incertitude et le risque sont nos ennemis.
Il y a le risque métier : construit-on la bonne chose ?
Il y a le risque social : ces personnes peuvent-elles la construire ?
Il y a le risque technique : Ça marchera sur la plateforme cible ?
Ça passera bien à l’échelle ?
Et il y a les risques sur les couts et les délais : Peut-on finir dans des délais raisonnables ? Et avec des coûts raisonnables ?
La connaissance peut être vue comme le contraire du risque.
Donc quand l’incertitude est grande, on se concentre sur l’acquisition de connaissance, comme des prototypes d’interface utilisateur, ou des expérimentations techniques (Spikes).
Peut-être pas trop excitant pour les clients, mais cela a de la valeur car on réduit les risques.
Du point de vue du client, la courbe ressemble à ça au début.
Et comme l’incertitude diminue, on se concentre progressivement sur la valeur client.
On sait ce qu’on va construire et comment, alors allons-y !
Et en commençant par les US de plus grande valeur, on obtient cette belle courbe de valeur escarpée.
Puis progressivement, la courbe s’aplatit.
On a produit les choses les plus importantes, maintenant, on ajoute simplement les fonctionnalités « bonus », les garnitures sur la crème glacée.
C’est un endroit confortable car à tout moment Pat et l’Equipe peuvent décider de « couper la queue » de liste Couper juste ici Et passer à un autre projet plus important, ou commencer un tout nouveau domaine fonctionnel sur le même produit.
C’est ça l’agilité métier.
Donc quand je parle de Valeur ici, je parle en fait de valeur-Connaissance + de valeur-Client.
Et on doit trouver un compromis entre ces valeurs.
Un autre compromis est : penser à court terme ou à long terme.
Que doit-on faire maintenant ?
Traiter ces bugs urgents ou développer cette nouvelle fonction géniale qui va éblouir les utilisateurs, ou cette mise à jour de plateforme difficile qui va sûrement nous permettre de développer plus rapidement par la suite ?
On doit en permanence trouver l’équilibre entre le travail réactif et le travail préventif “Combattre le feu” ou “éviter qu’il y ait le feu”.
Un autre type de compromis : Doit-on se focaliser sur « faire les bonnes choses » ? ou « bien faire les choses » ? ou peut-être « faire les choses rapidement » ?
Idéalement, on veut les trois, mais pas facile de trouver l’équilibre.
Supposons qu’on soit ici : on veut faire le produit parfait avec son architecture parfaite si on passe trop de temps à essayer d’être parfait, on peut rater une période de mise sur le marché, ou avoir des problèmes de trésorerie.
Supposons qu’on est ici, on se dépêche de transformer un prototype en produit utilisable.
Super pour le court terme, peut-être, mais sur le long terme, on peut se noyer dans la dette technique et notre vélocité s’approcher de zéro.
Supposons qu’on est ici, on construit une superbe cathédrale en un temps record.
Sauf que les utilisateurs n’avaient pas besoin d’une cathédrale mais d’un camping-car.
Il y a une tension saine entre les différents rôles Scrum.
Les PO se concentrent sur « construire les bonnes choses », les Equipes sur « bien construire les choses ».
Et les Scrummasters ou coaches agiles sur « raccourcir la boucle de feedback ».
Ça vaut le coût d’insister sur la vitesse.
Car une boucle de feedback courte accélèrera l’apprentissage, on apprendra plus rapidement ce qu’est « la bonne chose », et comment « bien la faire ».
Les trois vues sont importantes, essayez de trouver l’équilibre.
Il y a enfin le compromis entre développer un nouveau produit et améliorer un ancien produit.
« Product Backlog » est un terme assez déroutant car il sous-entend qu’il n’y a qu’un seul produit.
Et « projet » est aussi ambigu, il sous-entend que les développements ont une fin.
Mais un produit n’est jamais vraiment « terminé », il y a toujours de la maintenance et des améliorations à faire, tout au long de la vie du produit, jusqu’au moment ou il est définitivement arrêté.
Donc quand une équipe commence à développer un nouveau produit, que se passe-t-il pour le précédent ?
Transmettre un produit d’une équipe à une autre est couteux et risqué.
Un scénario plus habituel est que l’équipe continue à maintenir l’ancien produit tout en développant le nouveau.
Donc on n’a plus vraiment un PBL, mais plutôt un Backlog d’Equipe – une liste de choses que le PO veut que l’Equipe produise – et ça peut être un mélange de choses pour différents produits sur lesquel le PO doit trouver des compromis en permanence.
De temps en temps, un Participant appellera Pat et dira : « Hé, mon truc sera fini quand ? », ou « j’aurai quoi de ce que j’ai demandé à noël ? ».
En tant que PO, Pat est responsable de la gestion des attentes, ou plutôt des attentes réalistes.
Ça veut dire : pas de mensonge.
Je sais, c’est pas facile, mais qui a dit que l’Agilité, c’était facile ?
Ce n’est pas si difficile de faire une prévision, tant qu’elle ne doit pas forcément être exacte.
Si vous mesurez la vélocité de votre Equipe, ou de toutes vos Equipes, vous pouvez dessiner un burnup chart.
Comme ça.
Ce graphe montre le nombre cumulé d’US au cours du temps ou de story points si vous préférez.
Notez la différence : cette courbe montre une production, celle-ci, un résultat.
C’est la sortie, et c’est le résultat qu’on espère atteindre avec la production.
Notre but n’est pas d’avoir le plus de production possible, mais d’atteindre le résultat voulu – des PP contentes – avec le moins de production possible.
Moins, c’est plus.
Regardez le burn up chart et dessinez les courbes de tendance optimiste et pessimiste.
On peut faire ça avec statistiques vaudoues fantaisistes ou juste à la main.
L’écart entre ces lignes dépend bien sûr de la prédictibilité de votre vélocité.
Heureusement, elle tend à se stabiliser dans le temps, donc notre cône d’incertitude devrait s’affiner de plus en plus.
OK, retour sur la gestion des attentes.
Supposons que les PP demandent à Pat « Quand tout ÇA va être fait ? » « Quand serons-nous ici ? »
C’est une question périmètre fixe/temps variable.
Pat utilise les 2 lignes de tendance pour répondre « le plus probablement entre avril et mi-mai »
Supposons que les PP demandent à Pat : « On en aura combien à noël ? »
C’est une question temps fixe, périmètre variable.
Les lignes de tendance nous disent « on aura probablement fini tout ça, à noël, un peu de ça et rien de ça »
Enfin, supposons que les PP disent : « Peut-on avoir CES fonctionnalités la pour noël ? »
C’est une question à périmètre fixe et temps fixe.
En regardant les courbes de tendance, Pat dit « Non désolée, ça n’arrivera pas » suivi de : « voila ce qui peut être fait pour noël » ou « voila de combien de temps on a besoin pour tout faire »
C’est généralement mieux de réduire le périmètre plutôt que d’allonger les délais car si on réduit en premier le périmètre, on aura toujours le temps d’allonger les délais par la suite pour ajouter le reste des US.
L’inverse ne fonctionne pas parce que –flûte !!– on ne peut pas remonter le temps !
C’est connu : Le temps est assez pénible pour ça !
Pat le dit comme ça : « on peut livrer quelque chose ici, et le reste après, ou alors rien ici, et le reste après. Vous préférez quoi ? »
Les calculs sont simples à faire, donc Pat met à jour les prévision toutes les semaines.
Le plus important ici, c’est qu’on utilise des vraies données pour faire les prévisions, et on est honnête sur l’incertitude.
J’avais pas dit “pas de mensonges”, pas vrai ?
Et c’est un moyen très honnête de communiquer avec les PP, et en général ils apprécient beaucoup.
Si votre organisation n’aime pas la vérité et l’honnêteté, elle n’aimera probablement pas l’agilité.
Petit avertissement cependant : Si l’équipe accumule de la dette technique –s’ils n’écrivent pas de tests, et n’améliorent pas l’architecture en permanence– ils seront de plus en plus lents au fil du temps et la courbe de burnup s’aplatira progressivement.
Ce qui rendra quasiment impossible pour Pat de faire des prévisions.
Donc l’équipe est responsable du maintien d’un rythme soutenable, et Pat évite de les mettre sous pression en prenant des raccourcis.
Et si on avait un projet plus gros avec des équipes multiples ?
Et plusieurs PO, chacun avec son backlog pour une partie différente du produit.
Globalement, le modèle est le même.
On a toujours besoin de gérer la capacité, on a toujours besoin de communiquer avec les PP, on a toujours besoin de PO qui peuvent dire NON, on a toujours besoin d’affiner le backlog on a toujours besoin de feedbacks rapides, etc.
La vélocité est la somme de toutes les sorties et peut être utilisée pour faire les prévisions.
Ou faites des prévisions distinctes pour chaque équipe si cela a plus de sens.
Dans un scénario multi-équipes cependant, les PO ont une responsabilité supplémentaire très importante : se parler entre eux !
On doit organiser les équipes et les backlogs pour réduire les dépendances.
Mais il y aura toujours des dépendances.
On a donc besoin d’une synchronisation entre les PO pour construire les choses dans le bon ordre et pour éviter la sous-optimisation.
Dans les gros projets, on fait généralement appel à une sorte de Chef des PO pour synchroniser les PO.
Voila, c’est fini !
C’était le métier de PO en 2 mots ![]()
J’espère que ça vous a été utile.
About the Author
Réussissez vos projets en respectant délais, coûts et qualité grâce aux méthodologies en Gestion de Projet. A propos de l'auteur: Karim Abdi.
[...] [...]